Toto je vývojová dokumentace k programu Links. Najdete zde popis činnosti programu, popis jednotlivých rozhraní, rozdělení na moduly, popis jednotlivých modulů, popis významných funkcí a informace, jak případně psát další části prohlížeče. Tištěná verze dokumentace neobsahuje popis interních rozhraní programu, ta jsou v plné verzi dokumentace uložené na CD.
V adresáři links-2.0 , kde jsou zdrojové texty Links, najdete tyto podadresáře:
Tento program vyrábí z arrow.png (který je ve formátu PNG, kde barvy číslo 0,1,2 udávají šipečku, okolí a průhlednost) do arrow.inc , který obsahuje řady 32-bitových čísel, pro šipečku i pro její průhlednostní masku. Šířka šipečky musí být 32 pixelů.
Tento program vyrábí černě až bíle vybarvenou obrazovku, v 256 stupních. Pracuje v truecolor režimu 640x480x16M. Používá se k měření gamma monitoru pomocí měřiče světla (hardwarového to zařízení).
Obsahuje texty o různých barvách. Vhodné pro testování Links v grafickém režimu, zejména ditherování, zmenšování písmenek a správné gammy.
Vezme soubory v adresáři font a vyrobí z nich soubor font\_include.c , který se přikompiluje do programu a obsahuje interní strukturu obsahující font ve formátu PNG. Tato data jsou tím pádem uložena ve spustitelném souboru links a uživatel není obtěžován žádnými dodatečnými datovými adresáři, čímž se silně zvyšuje přenositelnost celého systému (nebylo jasné, kam by se měly tyto soubory umisťovat, neboť takováto místa vhodná pro umisťování těchto souborů jsou silně závislá na konkrétním typu systému a vznikaly by s tím jen problémy).
Fonty se do systému přidávají tak, že se přidá do adresáře font , pak se pustí generate\_font a pak se překompiluje links příkazem make . Detailnější popis je v kapitolách Přidávání fontů z Ghostscriptu a Přidávání fontů z tištěné předlohy.
Je určen k výrobě linksových fontů z fontů v Ghostscriptu. Vyrobí soubor letters.ps , který obsahuje všechna písmena od 0 do 255 tohoto fontu, přičemž kolem nich jsou boxy pro správné oříznutí. Tento program není určen pro ruční spouštění.
Uvnitř zdrojáku genps.c uživatel může nastavit proměnné h\_margin, v\_margin, font\_pos, font\_height, paper\_height . Viz následující obrázek:
paper\_height musí odpovídat výšce papíru, která je nastavena v pdf2html , tedy A4 (není důvod ji měnit), což je 297. Rozměrem těchto všech proměnných je 1 milimetr.
Program improcess představuje nástroj pro základní manipulace s černobílými obrázky PNG. Program nahraje obrázek, provádí na něm unární operace (není tedy možno kombinovat dva obrázky do sebe) a nakonec jej uloží do souboru. Syntaxe je
improcess infile cmdfile outfilekde infile je původní obrázek, outfile nový a cmdfile soubor s příkazy. infile může být totožné s outfile , k destrukci dat při tom nedojde.
cmdfile obsahuje řádky, kde každý řádek definuje jeden příkaz. Příkazy jsou tvaru příkaz argument argument \dots , kde argument může být pouze znaménkové decimální nebo hexadecimální (s 0x prefixem) číslo. Šedé tóny jsou reprezentovány čísly typu int, kde 0 je černá, 0xffffff bílá a při operacích je možno vyjet až do rozsahu -0x80000000 až 0x7fffffff , přičemž dále dojde k přetečení a nedefinovanému stupni šedé. Čísla v argumentu udávající barvu se řídí také touto konvencí.
Program umí následující příkazy:
Neplatný příkaz bude ignorován a bude se pokračovat v provádění. Před uložením do souboru musejí být všechny pixely mezi černou a bílou, budou-li mimo tento rozsah, jejich hodnota v souboru bude nedefinovaná.
Typické použití programu je pro ztluštění nebo ztenčení písmenek, které se provede gaussovským rozmazáním, vynásobením, přičtením a ořezáním.
Je shellový skript, který vyrobí font do adresáře ./font/ , přičemž typ fontu je definován v souboru Fontmap . Musí se spouštět z adresáře, ve kterém jsou zdrojáky prohlížeče. Je určen k ručnímu spouštění. Na systému musí být nainstalován Ghostscript .
Vyrábí z toku dat ve formátu více zkonkatenovaných souborů pbm (což je přesně formát který teče z ghostscript a ve skriptu pdf2html ) sérii png 17-násobným vodorovně a 15-násobným svisle převzorkováním. Není určen pro ruční spouštění.
Je skript, který vyrobí z *.pdf nebo *.ps sérii png souborů. Provádí převzorkování 15-násobné svisle a 17-násobné vodorovně do 8-bitové stupnice šedé. Výstupní gamma je 1.0. Výstupní obrázek obsahuje chunk gAMA (informace o gamma obrázku) a tento je nastaven na 1.0. Volá program pbm2png .
Pak pustíme wb02links , přičemž font\_cache.dat musí být v aktuálním adresáři. Vygenerují se png obrázky do adresáře ./font/ .
\penalty-10000
V adresáři Unicode se nacházejí tabulky znakových sad. Slouží k překladu z různých znakových sad do unikódu. Podmínkou pro znakovou sadu je, že musí být osmibitová, tedy obsahovat maximálně 256 znaků. To je důvod, proč do Links nejdou přidat tabulky například pro čínštinu nebo japonštinu.
Tabulky jsou uloženy v souborech s příponou .cp . Soubory jsou v textovém formátu, který se následně přeloží do zdrojových textů jazyka C. Formát souboru je následující:
ISO 8859-2
"ISO-8859-2", "8859-2", "latin2", "iso-latin2", "iso8859-2"
Soubor 7bit.cp obsahuje tabulku pro 7-bitové ASCII kódování.
V souboru index.txt v adresáři Unicode je seznam jednotlivých překladových tabulek. V souboru je na každém řádku název souboru s kódováním, ale bez přípony .cp . Například:
8859_1 8859_2 mac_lat2 utf_8 cp850Pořadí řádků může být libovolné.
Skripty gen-cp a gen-7b vygenerujete z tabulek soubory:
V souborech s příponou .lnx jsou tabulky pro překlad HTML entit do unikódu. Skriptem gen-ent se z nich vygeneruje překladová tabulka v jazyce C s názvem entity.inc .
Skriptem gen se spustí všechny výše uvedené skripty.
Ke spuštění skriptů je potřeba unixové prostředí s programy awk a sed .
Jazykové překlady fungují následovně. Každý text má číslo. K těmto číslům existují definované konstanty T\_xxx . Tyto konstanty jsou definované v souboru language.h . Soubor language.h je automaticky generovaný, takže by se do něj nemělo nic připisovat. Taktéž se pro odkaz na text musí používat pouze makra T\_xxx a ne čísla, protože čísla se mohou měnit. Protože spousta funkcí očekává řetězec unsigned char * , existuje makro TEXT(číslo) , které z čísla T\_xxx udělá pointer na řetězec. S takovým pointerem se nesmí dělat žádné operace krom předání následujícímu makru.
Dále existuje makro \_(unsigned char *, struct terminal *) , které přeloží řetězec. Prvním argumentem je řetězec, pokud je řetězec získaný makrem TEXT() , tak tento řetězec bude přeložen do příslušného jazyka. Pokud je řetězec získaný jinak (například "xxx", nebo naalokovaný na haldě, nebo cokoliv jiného), tak makro \_() vrátí tento řetězec beze změny. Druhým argumentem je terminál, na kterém se bude zobrazovat. Protože v textovém módu může být terminálů víc a každý může mít jinou znakovou sadu, bude se výsledek podle terminálu lišit.
Na místě, kde se v programu řetězec používá, se použije TEXT(T\_xxx) , pokud se řetězec bude předávat bfu vrstvě (menu, dialogy, atd.) --- bfu vrstva sama volá makro \_() . Pokud se řetězec bude tisknout rovnou (v textovém či grafickém módu), použije se \_(TEXT(T\_xxx), term) .
V adresáři intl se nacházejí soubory jazykových překladů v této části popíšeme strukturu těchto souborů.
Překlady jsou uloženy v souborech s příponou .lng . Názvy souborů jsou odvozeny od názvu příslušného jazyka. Referenčním překladovým souborem je english.lng , od kterého se ostatní překlady odvíjí.
Soubory .lng jsou textové, řádkově orientované a mají následující strukturu:
V souboru index.txt je seznam všech překladových souborů, na každém řádku jeden soubor, soubory jsou zde uvedeny bez přípony. Tedy například:
english brazilian_portuguese bulgarian catalan czech dutch estonian finnish french
V adresáři jsou skripty synclang a gen-intl . Skriptem synclang synchronisujete english.lng s ostatními jazyky. Po spuštění tohoto skriptu budou ve všech .lng souborech řádky se stejnými konstantami, tam, kde byl pro příslušný řádek nějaký překlad, bude stejný překlad i po doběhnutí skriptu, tam, kde překlad nebyl, bude NULL.
Skript gen-intl vygeneruje z tabulek C zdrojáky pro zakompilování do Links. Skript vygeneruje v hlavním adresáři Links soubory language.h a language.inc .
Pokud přidáváte nový řetězec, který se má přeložit, přidejte jej nejprve do english.lng , pak pusťte skript synclang , v ostatních jazycích na příslušné řádce NULL nahraďte příslušným překladem a nakonec pusťte gen-intl . Pak budete moci přidaný řetězec používat ve zdrojácích.
Prohlížeč po svém prvním spuštění vytvoří adresář .links , buďto v domovském adresáři uživatele (když je nastavena proměnná prostředí \$HOME ), nebo v adresáři se spustitelným souborem. Do tohoto adresáře se ukládají veškeré konfigurační informace, záložky a historie. Obsahuje tyto soubory:
Soubory jsou čistě textové, tedy se znalostí jejich vnitřní struktury je lze upravovat libovolným textovým editorem.
Záložky jsou uloženy ve formátu kompatibilním s prohlížečem Netscape 4.X. Tedy
v HTML, kde jsou adresáře realisovány konstrukcí Záložky se ukládají v kódování, které si uživatel zvolí. Základní nastavení je
UTF-8.
Pokud si uživatel nastaví jiný soubor pro ukládání záložek, záložky se budou
ukládat do daného souboru. Do souboru .links/bookmarks.html
se záložky
ukládají při základním nastavení.
Ukázka vnitřní struktury souboru:
links.his
obsahuje historii navštívených URL. Tato historie se použije v
dialogu pro zadávání URL. Struktura souboru je velmi jednoduchá. Na každém
řádku je napsáno jedno URL.
Struktura konfiguračních souborů links.cfg
a html.cfg
je stejná. Jedná
se o textové soubory, kde je na každém řádku uveden název konfigurační proměnné
a za ním po mezeře následuje hodnota, případně, pokud se proměnná skládá z více
hodnot najednou, mezerami oddělený seznam hodnot.
Na pořadí jednotlivých řádků v souboru nezáleží. Komentáře se uvozují znakem
vězení "\#" a končí s koncem řádku.
Názvy proměnných tedy nesmí obsahovat mezeru, proto se v názvu místo mezery
používá podtržítko. Řetězce se ukládají do uvozovek, aby se do nich dala zapsat
i mezera. Čísla se ukládají klasicky, reálná čísla též klasicky s tečkou.
Název kódové stránky se ukládá v textové podobě, stejně jak je uveden v
překódovacích tabulkách, ukládá se bez uvozovek. Například ISO-8859-2
.
Názvy jednotlivých konfiguračních proměnných nemá smysl uvádět, protože s
přidáním nové volby do nastavení prohlížeče typicky přibyde nová konfigurační
proměnná, navíc název je intuitivní. Tedy pouze pro ilustraci:
Do html.cfg
se ukládá pouze nastavení z dialogu "HTML nastavení". Do
links.cfg
se ukládá veškerá zbylá konfigurace.
Nahrávání a ukládání konfigurace se nachází v default.c
, kde je tabulka
struktur links\_options
, ve které jsou popsány jednotlivé konfigurační
proměnné, jejich názvy, mezní hodnoty a funkce pro čtení a zápis.
Tuto kapitolu by si měl přečíst každý, kdo do Links bude něco programovat. Jsou zde
uvedena pravidla, která je nutno při zasahování do prohlížeče dodržovat.
Links je psán celý v C, C++ se nepoužívá. Links je psán tak, aby byl
zkompilovatelný klasickým ANSI C bez GNU rozšíření. Je třeba dát pozor na
následující rozšíření, která sice projdou v gcc, ale neprojdou v ANSI C
(a kterých byl původní Links plný a dostávali jsme na to stížnosti):
C++ komentáře
Label na konci bloku
Inicialisace struktur nekonstantními výrazy
int a1, a2;
fn()
{
struct bla x = {a1, a2};
}}
K otestování přenositelnosti Links na ANSI C je třeba ho nahrát na Solarisy
nebo Irixy na Malé Straně a napsat (za současného modlení aby na Irixu
nespadl slabostí kernel):
Napíšeme foo.c
. Přidáme do Makefile.am
do řádku links\_SOURCES
foo.c
a na začátek foo.c
přidáme:
Po přidání do Makefile.am
je potřeba spustit automake
a autoconf
,
které znovu vygenerují Makefile
, teprve pak se po spuštění make
bude
kompilovat i přidaný foo.c
.
configure.in
je shell script, ve kterém jsou makra. Makra jsou procesorem
m4
expandována na další příkazy shellu (jak psát portabilní shell skripty
se dočtete v info autoconf
). Řetězce se v m4
dávají do $[$ hranatých závorek $]$.
Nejčastěji používaná makra:
Další makra --- viz info autoconf
.
Nesmí se předpokládat, že sizeof(int) == sizeof(void *)
. Neplatí to na
Alphě. Je možno předpokládat, že sizeof(int) <= sizeof(void *) <=
sizeof(long)
.
char
je na některých systémech signed
a na některých (třeba IRIXy na
Malé Straně) unsigned
. Aby se zabránilo chybám (jaké v původním browseru Links\
také skutečně byly), tak se před každý char
bude psát unsigned
.
char
bez specifikace se v kódu vyskytnout nesmí, signed char
se může
použít, když je znaménko potřeba.
Nepoužívat malloc, realloc, free
. Místo nich používat mem\_alloc
,
mem\_realloc, mem\_free
. Tyto funkce mají navíc kontrolu na memory leaky.
Když se vyskytne leak, tak se při ukončení napíše soubor a řádek, kde se
příslušná paměť alokovala, a dumpne core.
Následující funkce je třeba volat při různých chybových stavech. f/printf
by se pokud možno nemělo používat vůbec --- třeba jednoho dne bude potřeba
zpracovávání chyb změnit.
Pro práci s řetězci jsou v Links k disposici tyto funkce:
Následující funkce patří k sobě a mohou být používány pouze na řetězcích
vytvořených pomocí init\_str()
.
Datová struktura reprezentuje posloupnost znaků, z nichž žádný není nulový
(tedy to, co se myslí pod pojmem řetězec v jazyce C). Instance této struktury
je definována ukazatelem a délkou. Délka je vždy >=0
, a vyjadřuje počet těch
znaků, které jsou reprezentovány. Ukazatel je vždy různý od NULL. Podíváme-li
se do paměti, na kterou ukazuje ukazatel, uvidíme tam obsah této datové
struktury, za kterým bude nulový znak (terminátor), a na další obsah této
paměti se již nesmí koukat. Ukazatel vždy vznikl z mem\_alloc
nebo
mem\_realloc
. Destrukce struktury se provádí tak, že se zavolá
mem\_free
na ukazatel. Konstrukce se nesmí dělat pokoutně, musí se použít
init\_str()
. Datová struktura je implementována exponenciálni prealokací o
základu 2. Kód těchto funkcí je v souboru links.h
.
Funkce se používají tak, že se inicialisuje řetězec funkcí init\_str()
,
vytvoří se integerová proměnná a nainicialisuje se nulou. Dalším funkcím se
předávají ukazatelé na řetězec a integerovou proměnnou. Po práci s řetězcem se
na řetězec zavolá mem\_free()
.
Typické použití těchto funkcí vypadá asi takto. Je to poměrne efektivní,
protože funkce dělají prealokaci (exponenciální) a tak nevolají realloc
při
každém přidání.
Toto je špatně:
Pokud nějakou strukturu chceme řetězit v seznamu, musíme zajistit, aby první
dva prvky té struktury byly pointery na následující a předchozí položku
(next
a prev
). Pokud budou položky next
a prev
na jiném místě,
bude se do struktury střílet! Příklad:
Pro práci se seznamy slouží následující makra:
Kód by měl být psán tak, aby uživatelé, kteří chtějí pouze textový prohlížeč,
nebyli zatěžováni spoustou grafických funkcí. Textový prohlížeč by měl zůstat
rozumně malý. Pokud je Links zkompilován pro textový i grafický mód, je
definováno makro G
. Proměnná F
určuje, zda se právě běží v textovém(0) nebo
grafickém(1) módu. Pokud byl browser zkompilován pouze pro textový mód, je
F
makro, které je definované na hodnotu 0. Typický kód, mající se rozdvojit
podle módu, vypadá takto:
Při konfiguraci Links (před kompilací) je možno vypnout javascript. Proto je potřeba
kód javascriptu kompilovat pouze, když je javascript zapnutý. K tomu slouží makro JS
.
Veškerý kód javascriptu tedy musí být uzavřen mezi \#ifdef JS
a \#endif
. Tedy
takto:
Podle definovanosti konstant DEBUZIM
a BRUTALDEBUG
se vypisují nebo nevypisují
hlášky o tom, jak probíha analýza. Závislost na ničem není. Podobně fungují
i makra debug
(původní debug
oddefinováno v ipret.c
a ns.c
)
a idebug
(v builtin.c
, context.c
). Buďto jsou definována jako printf
, nebo
se místo nich vloží prázdné místo, normálně jsou vypnuté. Pak jsou tu
konstanty DEBUGMEMORY
--- podle ní se nastavuje komentář k argumentům
uloženým na bufferu, DEBUZ\_KRACHY
--- při internalu a js_erroru vysype
do links\_debug.err
údaje o místě, kde k chybě došlo. Konstanta DEBUZ\_KRACHY
je poněkud nebezpečná a v normálním provozu by neměla být definována!
U konstanty DEBUGMEMORY
je důležité, aby byla nastavena jenom když se
alokuje pomoci debug\_mem\_alloc
a freeuje pomocí debug\_mem\_free
, proto
je kolem nich v struct.h
\#ifdef
na to, jestli je DEBUGLEVEL
rovna 2.
Modul session
zajišťuje managemenet formátování, natahování a zobrazování
dokumentů a volání javascriptu. Modul též obsahuje cache na zformátované
dokumenty. Zdrojové texty najdete v souboru session.c
. Tento modul žádnou
z výše popsaných funkcí sám nevykonává, pouze se stará o jejich správu a
volá další moduly, aby práci vykonaly.
Ke stahování objektů slouží object requester
, v obrázku je vyznačen jako
modul objreq
, zdrojový kód je umístěn do souboru objreq.c
. Object
requester se stará o vyžadování dokumentů ze sítě, přesměrování a stahování. Samotné
stahování souborů nevyřizuje, pouze zařazuje požadavky do fronty scheduleru. Object
requester a všechny části pod ním pracují pouze s celými soubory. To znamená, že soubory
nijak neinterpretují, nedekódují a podobně. Pokud kterákoliv jiná část prohlížeče chce
stahnout nějaký soubor, zavolá právě funkci object requesteru.
Modul sched
, který se nachází v souboru sched.c
, je scheduler requestů. Úzce
spolupracuje s object requesterem, od kterého přijímá requesty a vyřizuje je. Na druhé
straně spolupracuje s cachí na stažené soubory (modul cache
), přidává do ní nové
soubory, pokud se soubor nachází v cachi, vrátí ho z cache. Scheduler
requestů rozděluje požadavky (které nejsou vyřízeny cachí) mezi jednotlivé protokoly:
http, https, ftp, finger, file. Scheduler také spolupracuje s modulem url
, s jehož
pomocí dekóduje URL a zjišťuje, jaký protokol má požadavek vyřídit.
Chování scheduleru requestů ovlivňují uživatelsky nastavitelné parametry v "nastavení
sítě": maximální počet spojení, maximální počet spojení k jednomu stroji, počet pokusů,
atd.
Modul cache
se nachází v souboru cache.c
. Tento modul je souborová cache. Do ní
se ukládají již stažené soubory. Chování cache ovlivňuje parametr "velikost cache", který
si uživatel může nastavit. Modul se stará též o vyhazování souborů z cache.
Souborová cache používá strategii LRU, ale poněkud modifikovanou --- dříve vyřazuje velké
soubory (zvýhodňuje malé soubory). Cache se po přidání nového souboru a při určování,
které soubory vyřadit, prochází na tři průchody. V prvním průchodu se prochází soubory od
nejstaršího směrem k mladším a dokud velikost přesahuje určitou mez, soubory se označí
k vymazání. Ve druhém průchodu se prochází cache od nejmladších souborů a pokud se
nalezne označený soubor, který by šel ještě ponechat v cachi, aniž by byla překročena
velikost cache, soubor se odznačí. Nakonec ve třetím průchodu se označené soubory
z cache odstraní. Při stahování do souboru (funkce "download" nebo "stahování")
se soubory do cache neukládají, pokud jejich velikost přesahuje čtvrtinu maximální
velikosti cache.
Modul url
, který se nachází v souboru url.c
, je soubor funkcí pro práci s URL.
Obsahuje funkce pro parsování URL: rozdělení na části protokol, port, uživatel, heslo,
server, adresář, .... Dále obsahuje funkce na spojování URL (vytváření absolutního URL
z relativního) a tabulku protokolů (které funkce se mají zavolat na který protokol,
parametry jednotlivých protokolů). Funkce z modulu url
jsou volány i z jiných modulů,
zejména funkce pro parsování a spojování URL, tyto závislosti v obrázku pro jednoduchost
nejsou nakresleny.
Moduly http
, https
, finger
, ftp
a file
najdete v stejně pojmenovaných
*.c
zdrojových souborech. Tyto moduly zajišťují rozhraní jednotlivých protokolů.
Mají za úkol stahnout konkrétní soubor a komunikace s příslušnou protistranou je již na
nich. Modul http
spolupracuje ještě s modulem cookies
, v případě přijetí HTTP cookie.
Všechny moduly pro protokoly používají modul connect
(v souboru connect.c
, na
obrázku není pro jednoduchost uveden). Modul obsahuje funkce pro navazování spojení a pro
jednoduché I/O z/do bufferu.
Tento modul najdete v souboru cookies.c
. Obsahuje funkce pro práci s cookies. V
modulu je seznam všech cookies a seznam všech domén a funkce, které s cookies pracují:
funkce pro smazání cookie, vytvoření cookie, přijetí cookie, odmítnutí, poslání všech
cookies pro daný server. Tento modul je částečně využíván i rozhraním javascriptu,
protože javascript umožňuje práci s cookies, tento vztah v obrázku pro zjednodušení není
zakreslen.
Modul jsint
, který najdete v souboru jsint.c
, je rozhraní mezi javascriptem a
prohlížečem. Rozhraní javascriptu sahá do většiny částí prohlížeče a zakreslení všech
těchto vztahů by učinilo obrázek poněkud méně čitelným, proto jsou v obrázku zakresleny
pouze hlavní vztahy mezi session a interpretem javascriptu.
Rozhraní zejména obsahuje tzv. upcally
, neboli
funkce, které volá javascript kdykoliv chce modifikovat nebo přistupovat k
interním strukturám prohlížeče (dokument, rámy, okna, formuláře, obrázky,
odkazy, tlačítka, vnitřní proměnné, ...). Javascript se nikdy nesmí přímo
odkazovat ukazateli na konkrétní objekty v prohlížeči. Mohlo by se totiž stát,
že daný objekt přestane existovat a javascript se odkáže neplatným pointerem,
to by samozřejmě vedlo ke katastrofě. Proto se javascript odkazuje pomocí
čiselných identifikátorů jednotlivých objektů. Identifikátor je long
, který
v sobě má zakódován typ objektu a pak jednoznačnou identifikaci v rámci daného
typu. Pokud se javascript odkáže na neplatný objekt, nic se nestane, upcall nic
neprovede a vrátí se. V upcallech se také vždy testuje, zda
javascript má právo na ten konkrétní objekt přistupovat. Pokud ne, upcall se
ukončí (jako v případě odkázání na neexistující objekt).
Některé upcally se volají přímo a přímo vrací hodnotu, jiné je potřeba volat ze
select smyčky. Aby mohly upcally volané ze select smyčky vrátit nějakou
hodnotu, volají funkce zvané downcally
. Pomocí downcallů se vrátí hodnota z
upcallu do javascriptu. Pokud javascript zavolá upcall ze select smyčky,
zablokuje se a čeká na odpověď. Jakmile upcall zjistí požadované informace nebo
provede požadovanou činnost, zavolá downcall, který javascript odblokuje,
případně mu předá výsledek, a javascript pokračuje dále. Javascript se
zablokuje samozřejmě pouze v tom kontextu, který zavolal upcall, ostatní
kontexty běží dále.
Poslední součástí rozhraní javascriptu jsou funkce pro vytváření a rušení
kontextu javascriptu a pro spouštění javascriptu.
Modul javascr.l
je lexikální analyzátor vygenerovaný programem Flex
. Zdrojový
soubor v C je možno najít v javascr.c
, vstup pro Flex
pak v adresáři parser
v
souboru javascr.l
.
Úkolem lexikální analýzy je rozbít vstupní řetězec do sady tokenů, které postupují dále k
syntaktické analýze. Tokeny mohou být nemálo typů. Lexikální pravidla byla opsána z normy
javascript 1.1 od Netscape Corporation a poněkud upravena s vyhlídkou na snazší
syntaktickou analýzu. Např. každé řídící slovo má svůj vlastní typ tokenu (while
,
for
, ...). K syntaktické analýze postupují tokeny číslované typem long
(možná by
stačil int
, ale jelikož při jeho psaní nebylo jasné, jestli nebude potřeba místo
čísla vracet pointer, byl vybrán typ, který je konvertovatelný na pointer.
Lexikální analýza též odstraňuje komentáře a tomu podobné pro význam programu
nepotřebné věci (konce řádku, zbytečné mezery...).
Toto je modul syntaktické analýzy javascriptu. Syntaktický analyzátor je vygenerován
programem Bison
, zdrojový kód v C je v souboru javascript.c
.
\penalty-10000
Syntaktická analýza dostává na vstupu jednotlivé tokeny a má "říct, jak spolu souvisejí",
tedy postavit syntaktický strom podle pravidel gramatiky. Tuto gramatiku jsme téměř
opsali opět z normy javascript 1.1. Lexikální i syntaktická analýza předcházejí vlastní
interpretaci, jelikož interpretování "z čisté vody", tedy z čistého zdrojového kódu právě
interpretovaného javascriptu by bylo značně zdlouhavé, navíc bison neposkytuje dostatečně
komfortní prostředí pro samotnou interpretaci --- bylo by nutné udržovat pohromadě
syntaktický analyzér (který je už sám o sobě dost dlouhý) v jednom souboru s
interpretačními pravidly (ta jsou ještě delší). Syntaktický analyzér pouze podle pravidel
opsaných z gramatiky z posloupnosti tokenů postaví syntaktický strom tvaru: Šest argumentů není nikdy použito (maximum jsou čtyři, návrh natvrdo sestrojit sedmice je
podložen těmito argumenty: Sice je v určitém smyslu poněkud marnotratný (průměrný počet
potomků ve stromě je mezi dvěma a třemi), navíc není zcela pružný (změna gramatiky může
někde vynutit třeba 7 synů), zato je ale poměrně jednoduchý, není potřeba udržovat počet
synů a komplikovaně pro ně alokovat a odalokovávat paměť, navíc změna gramatiky by
reprezentovala takový zásah do interpretu, že přidání pár slotů na syny by byla nevinná
dětská hra (i když samotné přidání nějakých pravidel by rovněž problémem nebylo -
postačovalo by přidat příslušná pravidla do javascript.y, eventuálně nové tokeny do
javascr.l a změny interpretující funkce do ipret.c).
Generování interkódu probíhá při syntaktické analýze. Celý výpočet
javascriptu je zavřen ve struktuře struct js\_context
, která obsahuje zejména:
Builtin
je modul vestavěných funkcí, objektů a proměnných. Zdrojáky můžete najít v
souboru builtin.c
. Tento modul je volán z interpretu javascriptu, kdykoliv se
čte nebo zapisuje vestavěná proměnná. Vestavěný objekt je například matematika, práce s
řetězci, datum a další, pak samozřejmě vše co je na stránce, formuláře, odkazy, okna atd.
Z pohledu javascriptu se nepozná, zda je vestavěná proměnná, funkce či objekt "uvnitř"
prohlížeče (zda se například jedná o nějaký formulář na stránce a podobně), z hlediska
javascriptu je přístup na vestavěné proměnné a funkce jednotný. Pokud se jedná o
"vnitřní" součást prohlížeče, modul builtin zavolá upcall na přistoupení k danému
objektu.
Jak již bylo zmíněno, mezi vestavěné funkce a objekty patří matematika. Součástí
matematiky je i počítání MD5 sumy. Kód na práci s MD5 můžete nalézt v souborech
md5.c
, md5.h
, md5hl.c
. Tyto soubory nepsal nikdo z týmu projektu, jedná se o
externí kód stažený z webu.
Interpret mezikódu, modul ipret
je nejnáročnější částí celého interpretu. Jeho hlavní
část lze najít v souboru ipret.c
, v souboru ns.c
je možno najít funkce
obsluhující namespace. Interpretace probíhá tak, že funkce ipret
postupně a organizovaně prohlíží strom. Jediné, co potřebuje vědět, je, v kterém vrcholu
teď stojíme, kolikátý argument daného operátora zpracováváme a jaké argumenty už máme
spočítané. Když má operátor vypočteny všechny argumenty, spočítá svou hodnotu a vrátí
řízení "nadřazenému uzlu", který jeho výpočet použije jako jeden ze svých argumentů.
Důležité je, že argumenty se udržují na zásobníku argumentů a vlastnosti zásobníku
zaručují, že ve chvíli, kdy se budeme shánět po svých argumentech je tam budeme mít v
pořadí: poslední, předposlední, ... první (pokud nechceme jinak). Stejně tak teoretické
vlastnosti zásobníku zaručují, že vždy po ukončení výpočtu v současném uzlu se vrátíme do
bezprostředně předcházejícího uzlu, který má ještě zájem počítat (zájem počítat už např.
nemá operátor program, který již zavolal svůj druhý argument. Funkce program
vznikla
z pravidla: program->program program
, tedy pouze řetezí jednotlivé bloky programu.
Když je potřeba interpretování zastavit (dočasně ukončit), zavolá se
callback. Po tomto zavolání může interpret být ještě probuzen dalším požadavkem.
Je-li potřeba s příslušným skriptem již definitivně skoncovat, zavolá
se funkce
Moduly view
a view\_gr
můžete najít v souborech view
a view\_gr.c
. Modul
view
má na starost zobrazování dokumentu a pohyb po dokumentu, view\_gr
zobrazuje dokument v grafickém módu. Najdete zde sazeč stránky pro textový i grafický
režim, funkce pro handlování uživatelských událostí jako je například kliknutí myší,
scroll posun stránky, vyplňování formuláře, hledání na stránce, přepínání rámů, otevírání
nového okna, ukládání dokumentu. Pak také vyřizování event handlerů javascriptu: OnClick,
OnMouseOver, OnMouseOut, ....
Z těchto modulů jsou volány "nižší" funkce pro čtení klávesnice, čtení myši, kreslení
na obrazovku, sázení textu, psaní na terminál a kreslení obrázků.
Tyto dva moduly zajišťují veškerou práci s obrázky, počínaje stahováním ze sítě a
kreslením konče. Modul img
se nachází v souboru img.c
, obsahuje funkce pro
vkládání obrázků do dokumentu, dekodéry jednotlivých obrazových formátů, které jsou
uloženy v souborech gif.c
, jpeg.c
, tiff.c
, png.c
, xbm.c
a funkce pro
vykreslování obrázků do dokumentu. img\_cache
je cache na dekodéry obrázků, ukládají
se do ní dekodéry ve všech stádiích běhu: ještě nespuštěné (čekající na stažení obrázku
ze sítě), běžící i doběhnuté (hotové dekódované a zditherované obrázky). Obrázkovou cache
najdete v souboru img\_cache.c
. Obrázková cache je klasická LRU cache, jejíž velikost
si uživatel může nastavit v menu.
Modul img
je volán také z rozhraní javascriptu upcally na změnu zdrojového URL
obrázku. Tento vztah pro jednoduchost není do diagramu zakreslen.
V modulu html
v souboru html.c
najdete kompletní parser HTML jazyka. V souboru
Skládá se zejména ze spousty funkcí, které parsují jednotlivé HTML elementy. html\_r
(v souboru html\_r.c
) je parser a sazeč HTML v textovém módu, html\_gr
(v souboru
html\_gr.c
) parser a sazeč v grafickém módu. Tyto dva moduly postupně parsují
dokument, vytvářejí jednotlivé objekty stránky a ukládají je na stránku. Grafický sazeč
stránky volá z modulu img
funkce pro vkládání obrázků. html\_tbl.c
je kód pro sázení
tabulek, jak v grafickém, tak i v textovém módu. Ten je volán grafickým a textovým
sazečem stránky. Modul html
volá modul charset
, který zajišťuje překlad kódování
znakových sad. Některé další části Links modul charset též volají, ale to není do
diagramu pro jednoduchost zakresleno. Chování sazeče HTML je ovlivněno "HTML nastavením"
v menu.
Veškeré uživatelsky interaktivní části Links jsou soustředěny do modulu bfu
, který
naleznete v souboru bfu.c
. Jsou zde funkce pro vytváření dialogů, menu, klikátek,
message boxů, okýnek s dotazem, s oznámením, okýnek pro zadávání textu. Dále pomocné funkce
pro vytváření vlastních dialogů: formátování tlačítek, checkboxů, radio tlačítek,
zadávacích políček, ....
V modulu menu
, který lze najít v souboru menu.c
, se nacházejí definice všech menu
v Links.
Tyto moduly volají funkce grafických driverů --- pro kreslení na ploch a čar na obrazovku
a funkce pro sázení písmen (modul dip
).
Grafické ovladače zahrnují moduly drivers
, svgalib
, x
, pmshell
, fb
,
atheo
s a terminal
.
Jednotné rozhraní pro grafické drivery se nachází v modulu drivers
, v souboru
drivers.c
. Toto rozhraní obsahuje jednoduchá grafická primitiva pro nakreslení čar,
vybarvení plochy, zaregistrování bitmapy, nakreslení bitmapy, vrácení barvy, scroll,
nastavení ořezávací plochy a další. Modul drivers
obsahuje ještě simulaci virtuálních
zařízení --- přepínání virtuálních grafických konzolí v Links jako emulace více oken
(například pro svgalib nebo framebuffer). V modulech svgalib
, x
, fb
,
pmshell
, atheos
(v souborech svgalib.c
, x.c
, fb.c
, pmshell.c
,
atheos.cpp
) se nacházejí implementace grafického rozhraní na jednotlivých grafických
systémech.
Modul terminal
(soubor terminal.c
) obsahuje rozhraní pro výstup na textový
terminál: psaní písmen, čtení událostí myši (z gpm), čtení z klávesnice, inicialisace,
ukončení, mazání obrazovky, .... Grafický driver fb
a modul pro výstup na terminál používají ještě
funkce pro čtení klávesnice ze souboru kbd.c
. Tento modul pro jednoduchost není
zakreslen v diagramu, modul obsahuje inicialisaci klávesnice a funkce pro čtení kláves.
Modul dip
provádí rendering písmen a bitmap v grafickém módu, tisk textu, aplikaci
gamma korekce, modul dither
provádí ditherování pomocí Floyd-Steinbergova algoritmu.
V souboru dither.c
jsou nízkoúrovňové ditherovací rutiny, v souboru dip.c
rutiny
na gamma korekci, alfa kanál, funkce pro nahrávání a výběr fontů, tisk řetězců. Součástí
souboru dip.c
je i font\_cache
--- cache na nascalovaná, zditherovaná písmenka s
již aplikovanou gamma korekcí. Cache používá metodu LRU pro uvolňování místa. Bitmapy
fontů, neboli modul font\_data
, jsou uloženy v souboru font\_include.c
ve formě
PNG souborů uložených v C zdrojáku.
Na obrázku nahoře je vidět důležité struktury prohlížeče a jejich vzájemnou
provázanost.
Obdélníčky na obrázku znázorňují jednotlivé struktury, šipky naznačují vazby mezi nimi
--- tedy ukazatele.
Pokud je u struktury napsáno "pole", znamená to, že ukazatel míří ne na strukturu, ale
na pole struktur. Názvy u šipek znamenají název příslušného pointeru. Šipky do kruhu
znázorňují kruhový seznam (jako například kruhový seznam struktur window
, na který ukazuje
ukazatel windows
ze struktury terminal
)
Struktura terminal
odpovídá jednomu oknu prohlížeče. Tedy po zavolání funkce "Otevři
nové okno" se vytvoří nová struktura terminal
. Struktura tedy odpovídá jednomu oknu
v okenním systému nebo jedné virtuální konzoli.
graphics\_device
je přítomna pouze v grafickém režimu a je ve vazbě 1:1 se
strukturou terminal
. Ze struktury terminal
ukazuje pointer windows
na kruhový seznam struktur
window
.
Struktura window
vyjadřuje plochu, na kterou lze kreslit a která dostává události od
klávesnice a myši. Takovouto plochou může být menu (struct menu
), hlavní menu
(struct main\_menu
), dialog (struct dialog\_data
) nebo plocha, kde se zobrazuje
HTML stránka (struct session
). Ukazatel data
míří na strukturu, která dále
popisuje tuto plochu. Plochy jsou navrstveny nad sebou, události propadávají od
nejvyšší k nejnižší vrstvě, dokud ji nějaká vrstva nezachytí a nezpracuje.
struct session
, jak již bylo řečeno, popisuje oblast, kde se zobrazuje HTML
stránka. Teoreticky koncepce Links umožňuje více session
na jednom terminálu,
v praxi je na jednom terminálu vždy jedna session
.
struct f\_data\_c
reprezentuje jeden rám na HTML stránce. Jelikož rámy v HTML
mohou mít podrámy, podrámy mohou obsahovat opět další podrámy atd., struktura obsahuje
kruhový seznam podrámů subframes
, jak znázorňují šipky do kruhu.
Ze struktury f\_data\_c
míří ukazatel vs
na strukturu view\_state
, která
obsahuje dynamické informace z příslušného f\_data\_c
. To je například pozice na
stránce, pozice ve vyhledávání a podobně. Mezi dynamické informace také patří stav
formulářů (vyplněné hodnoty, stav tlačítek atd.), které jsou reprezentovány polem struktur
form\_info
, na které z struct view\_state
míří stejnojmenný ukazatel. Každé
form\_info
odpovídá stavu jednoho elementu formuláře.
Statické informace o stránce jsou umístěny ve struct f\_data
, která se ukládá v
dokumentové cachi. Struktura f\_data
obsahuje pole odkazů (struktur link
),
kruhový seznam struktur tag
, což jsou tzv. anchors (místa v dokumentu, na která se
dá odkazovat, vzniknou konstrukcí ...
). Kruhový seznam struktur
form\_control
zachycuje statické informace o formulářích. Každá struktura
form\_control
odpovídá jednomu elementu formuláře.
Statický popis stránky se liší pro textový a pro grafický mód. V textovém módu je
stránka jednoduše popsána polem line
řádek na stránce, kde se každá řádka skládá z
pole znaků chr
.
V grafickém režimu je stránka popsána soustavou grafických objektů
g\_object\_area
, g\_object\_line
, g\_object\_image
, g\_object\_text
,
g\_object\_table
. g\_object\_area
popisuje obdélníkovou plochu v dokumentu.
Obsahuje pole řádků g\_object\_line
, kde každá řádka může být složena z textů
(g\_object\_text
), obrázků (g\_object\_image
) a tabulek (g\_object\_table
).
Tabulka je opět soustava objektů g\_object\_area
, které se opět skládají z řádek
atd.
Základem pro fonty jsou obrázky písmenek, tak jak mají vypadat. Písmo je bílé a papír černý.
Mezi tím jsou stupně šedé, protože písmenko je převzorkované z velkého rozlišení.
Tyto šedotónové obrázky jsou zakompilovány ve spustitelném souboru links a mají výšku typicky 112 pixelů, nicméně
mohou ji mít libovolnou. Souvislý text se skládá z
řádek, což jsou stejně vysoké pruhy textu. V obrázku písmenka (toho v adresáři font) je
horní okraj (horní hrana nejsvrchnější pixelové řady) ztotožněn s hraniční přímkou těchto
pruhů, a dolní hrana (dolní okraj nejspodnější pixelové řady) je stotožněna s hraniční
přímkou o jednu řadu níže. Hraniční přímka je útvar o nulové tloušťce.
Překrývání ani ligatury se nepodporují z důvodu, že přinášejí málo vizuálniho zlepšení za
cenu zavlečení obtížných problémů do sázení, tištění, scrollování, rozsvěcování části
textu a podobně. Italické písmo se nepodporuje z důvodu, že by mezera mezi písmeny z
důvodu překryvu byla někdy zaměnitelná s mezerou mezi slovy.
Partie, které jsou v obrázcích bílé, budou kresleny "inkoustem", partie černé budou
kresleny "papírem". Části s barvou mezi tím budou kresleny lineárně (ve fotonovém
prostoru) mezi tím (tedy např. je-li png 8-bitové a barva z rozsahu 0 (černá) -- 255
(bílá) je 12, pak bude smícháno 12/255 inkoustu a (255--12)/255 papíru). Když jsou
písmenka barevná (což se nedoporučuje, protože to má za následek zbytečné zvětšení PNG),
tak se zkonvertují na černobílé podle aproximační formulky vyjadřující přibližný jas
vnímaný člověkem.
Předlohy písmenek jsou hodně vysoké obrázky, například 112 pixelů. Pro kreslení řekněme
16 pixelů vysokého písmenka je třeba bitmapu zmenšit. Na to se použije algoritmus, který
namapuje výstupní pixely na vstupní (oboje pixely bere jako obdélníky) a v každém
výstupním pixelu vypočítá průměrnou barvu na základě informací o pixelech vstupních. Dělá
se to převzorkováním v jednom směru a následným převzorkováním v druhém směru. Pořadí se
volí tak, aby mezivýsledek měl tu menší plochu z obou možných variant.
Písmenka, která jsou moc titěrná, takto vyjdou správně - tedy tak, jak by se jevila,
kdyby byla natištěna na papíře a snímána idealizovaným scannerem
s dokonalým
objektivem a CCD prvkem se čtvercovými pixely, mezi nimiž nejsou mezery. Ovšem, jak je
mozno vidět v televizi při záběru na dokument s malým písmem (a jak také vyplývá z
naměřených funkcí vnímání kontrastu v závislosti na prostorové frekvenci u lidského oka),
když jsou písmenka malá, vypadají šedivě a nevýrazně. Je to způsobeno faktem, že malé
černé a bílé detaily vytvoří šedivou, která způsobuje subjektivní vjem sníženého
kontrastu. Tomuto se předchází následnou korekcí, která slučuje filtr pro zvýšení
konstrastu (s oříznutím na černou a bílou, samozřejmě) a filtr pro zvýšení ostrosti.
Parametry filtru byly voleny empiricky, aby to dobře vypadalo. Byly dělány také pokusy s
převzorkováním ostrou dolní propustí namísto mapování obdélníků, ale výsledek byl špatný
(ačkoliv metoda byla ta jediná matematicky správná pro převzorkování velkého obrazu na
malý tak, aby se reprezentovatelné frekvence zachovaly beze změny amplitudy i fáze).
Pro tento kombinovaný filtr je použita matice 3x3 bodů natvrdo zakódovaná do algoritmu (a
optimalizovaná na základě symetrie). Filtr se používá do výšky písmenek 32 pixelů, dále
se již nepoužívá.
Zdrojové PNG soubory jsou uloženy ve spustitelném souboru. Program generate\_font
slouží
pro výrobu font\_include.c
, jenž obsahuje pole bytů zapsané v syntaxi jazyka C, ve kterém
jsou uloženy po sobě v pořadí podle čísla znaků všechny potřebné PNG, a pomocnou tabulku
umožňující nalézt písmeno a zjistit, jak je jeho PNG dlouhé. PNG se v paměti rozkóduje
pomocí libpng a putuje dále do zpracování.
Výhody celého tohoto přístupu jsou následující: pro kompletní funkci prohlížeče je
potřeba jeden soubor a příslušné nainstalované knihovny (v případě, že je zkompilován
staticky, je třeba jen jeden spustitelný soubor, který může být teoreticky puštěn i misto initu),
nevznikají tedy potíže s tím, kam umístit data na různých operačních systémech. Vzhled a
podporované fonty nejsou platformně a konfiguračně závislé. Písmenka se dají snadno
přidávat (stačí získat vzor písmenka ve tvaru obrázku bez omezení na výšku a šířku, ten
je možno získat i z tištěného materiálu nascanováním, úpravou obrazu GIMPem a uložením ve
formátu PNG) pouhým překompilováním prohlížeče (což je standarní instalační procedura).
Písmenka jsou dobře čitelná i při malé pixelové výšce (na rozdíl od neantialiasovaných
fontů, které jsou při nízkých výškách téměř nebo zcela nečitelné).
Písmenka z PNG jsou standardně uložena 8-bitová šedá s gammou 1.0 což odpovídá tomu, že
jsou přímo úměrná světlu vycházejícímu z obrazkovky. Použijeme-li je jako alpha masku na
16-bitové barvy, vzniknou nám čísla 0 až 255*255*257. K tomuto číslu přičteme 127 a
vydělíme to 255, čímž dostaneme číslo v rozsahu 0--255*257 (65535).
Ruzné druhy písma jsou dělány tak, že každý druh písma má extra sadu obrázků. Podtržené
písmo se dělá přikreslováním podtrhávací čáry přes font: při kreslení znaků se nastaví
clip nad podtrhovací čáru, pak se nakreslí podtrhovací čára a clip se nastaví pod
podtrhovací čáru a nakreslí se písmenka znovu.
Jinak má každý font jméno ve formátu family-weight-slant-adstyl-spacing
. Family
může být
libovolné jméno (fonty ho mají malými písmeny, nehledí se na velká a malá písmena)
složené jen z písmen a podtržítek. weight
je "bold" nebo "medium", slant
je "italic" nebo
"roman", adstyl
je "sans" nebo "serif", spacing
je "mono" nebo "vari".
Když se hledá vhodný font, tak se napřed chce, aby seděly všechny položky co označují
font. Tím se najde v souboru font/catalogue
jediný font, který se dá na první místo a
vyškrtne se. Pak se zruší postupně položky family, adstyl, weight, spacing, slant
. Po
zrušení každé položky se projde katalog a vyhovující fonty se nasází na další místa.
Nakonec je průchod se zrušenými všemi položkami, a tam musí projít všechny fonty, takže
se všechny fonty tímto seřadí do žebříčku oblíbenosti pro zadaný požadavek na font. To se
nacpe do struktury struct font
, a když se hledá písmenko, tak se po hitparádě jde zezhora
dolů a dokavaď se nenajde, tak se jde. Když se nenajde ani na posledním místě, tak se
vrátí znak reprezentující chybějící písmenko (lebka, kaňka a podobně).
Do monitoru vstupuje elektrický signál a vystupuje z něj optický signál. Elektrický
signál je přímo úměrný počtu elektronů a optický signál počtu fotonů. Co je foton a
elektron snad každý ví. Všechny elektrony jsou stejně velké. Všechny fotony jedné vlnové
délky jsou stejně velké.
Počet fotonů není přímo úměrný počtu elektronů na vstupu. Platí například, že
$fotony=elektrony^{2.2}$. To 2.2 je gamma toho monitoru. Obdobné kalkulace platí i pro jiná
zařízení, pokud jsme schopni se dohodnout, v jakých jednotkách se měří vstupní a výstupní
veličiny zařízení. Ne každý monitor má gammu stejnou. A gamma jednoho exempláře monitoru
se může lišit i pro jednotlivé kanály red, green, blue. Nejlepší je proto gammu změřit
pomocí testovacího obrazce a nastavit ji do prohlížeče, protože pak dostaneme
nejdokonalejší obraz. Při zadání nesprávných hodnot gamma mohou vzniknout závady
zobrazování jako barevné závoje při ditherování, příliš kontrastní jedny partie obrazu a
nedostatečně kontrastní ostatní partie obrazu, případně nesprávné podání barevného tónu v
určitých partiích. V případě, že není možno určit gammu, lze použít aproximaci, kdy se
všechny tři gammy nastaví stejně, a to na hodnotu 2.2.
Základní podmínka pro to, abychom očekávali vůbec věrný obraz, je nastavit správně jas
monitoru. S kontrastem si pak budeme moct kroutit jak chceme, kvalitu obrazu neovlivní,
jen jeho intenzitu. Nastavovací procedura následuje: nastavte kontrast na minimum a jas
na maximum. Zmenšete obraz abyste jasně viděli rozdíl mezi rámečkem obrazu ještě
zasaženým elektronovým paprskem a krajem skla paprskem nezasaženým. Pak snižte jas dokud
nepřestane být vidět toto rozhraní. Pro zlepšení viditelnosti je vhodně zhasnout,
zatáhnout záclony a podobně. Jakmile rozhraní přestane být vidět, jas se již nesmí dále
ubírat. V tomto okamžiku velmi opatrně nalepte kus lepicí pásky na knoflík jasu aby se
již nedal nikdy více otáčet nebo se zapřísahejte na Bibli, že do elektronického menu již
nikdy na jas nesáhnete. Pak si nastavte kontrast dle libosti a zvětšete obraz zpět do
původní velikosti. V případě, že nejste proceduru schopni provést přesně, je lepší nechat
jas trochu větší než trochu menší. Přesný popis této procedury je
http://www.inforamp.net/ poynton/notes/brightness_and_contrast/index.html
Display gamma je gamma exponent mezi hodnotou vstupující do grafického ovladače
(například do paměti grafické karty, do X protokolu, atd.) a počtem fotonů vystupujících
z luminoforu obrazovky následkem ozáření elektronovým paprskem.
Jaký má display gamma exponent, to říkají proměnné display\_red\_gamma
,
display\_green\_gamma
a display\_blue\_gamma
. Protože gammy se mohou lišit pro
různé barevné kanály, tak jsou tam tři. Cílem zobrazení Links je, aby počet fotonů
dopadajícího do oka uživatele při osvětlení 64 luxů byl stejný jako počet fotonů
dopadajícího do oka uživatele, sedícího před monitorem s gammou monitoru 2.2 a gammou
obrázku 1/2.2 (obrázek podle sRGB standardu) při osvětlení 64 luxů.
V případě, že máme obrázek sRGB a monitor s gammou 2.2 a osvětlení 64 luxů, postupuje
Links následovně: vezme raw data z obrázku a pošle je do obrazovky. Pokud je osvětlení
jiné, hodí se před šoupnutím obrázek umocnit na následující čísla:
\table[|r|r|]
\topline
Osvětlení&\hfil Umocnit na\hfil\cr
\midline
$0\,$lx&1.333333333333\cr
$15\,$lx&1.111111111111\cr
$64\,$lx&1.000000000000\cr
$\geq200\,$lx&0.888888888888\cr
\botline
\endtable
Tato magická čísla označme jako user\_gamma
a nechme je nastavit uživatele.
V případě, že gammy monitoru jsou jiné, a gamma obrázku je jiná, dělají se tyto
akce:
Proto je ve zdrojovém kódu dip.c
wanted\_red\_gamma
, wanted\_green\_gamma
a
wanted\_blue\_gamma
. Jsou to gammy, které jsou zařazeny do obrazového řetězce
jako exponenciální funkce $x^-wanted_red_gamma$, $x^-wanted_green_gamma$,
$x^-wanted_blue_gamma$.
V přenosovém řetězci uvnitř linksu se dělají následující procedury:
V případě zobrazování obrázku z png, jpg, a podobně, se dělají náledující procedury:
Vzhledem k tomu, že nejrozumnější (a nejběžnější) je PNG a JPG obrázky ukládat
s gammou rovnou 0.45454545 (gamma sRGB standardu), nevzniká v řetězci
degradace, která by vznikla, přenášely-li by se někde 8-bitová data s gammou 1
(tedy úměrná osvětlení scény).
Zobrazovací systém se skládá ze dvou částí --- HTML parseru a sazeče HTML.
HTML parser se nachází v souboru html.c
. Vstupem do něj je funkce Tato funkce dostane argumenty html
a eof
, které znamenají odkud a kam se má
parsovat ve vstupním textu. Znak, na který ukazuje eof
a další znaky již nebudou zparsovány
.
Dále dostane pointery na funkce put\_chars
, line\_break
a special
. A konečně
poslední dva argumenty jsou data, která se předávají těmto funkcím a HTTP hlavička
head
. V HTTP hlavičce je například uložen "Refresh:", pokud se na daném URL vyskytuje. Slouží
parseru k tomu, aby se například podle refreshe mohl správně zařídit.
Funkce put\_chars
se volá, když chce parser vysázet řetězec. První argument jsou
data, která HTML parser dostane (data
), druhý argument je řetězec, který se má
vysázet, a třetí argument je délka, kolik znaků se má vysázet.
Funkce line\_break
je volána, když se má přejít na novou řádku. Dostává pouze jeden
argument, a to jsou opět data
, která HTML parser dostane pro tyto funkce.
Poslední z funkcí, funkce special
, se volá na různé speciální efekty (například
obrázek, rám, tabulka, ...). Prvním argumentem jsou opět data
, druhý argument je
identifikace akce --- jedno z maker SP\_xxx
. Další argumenty závisí na konkrétní
akci.
\def\zlom{{\hfil\penalty-10000}}
Zde je přehled jednotlivých maker speciálů SP\_xxx
a jejich význam:
\table[m{4pt}t{4pt}|l|p{10em}|p{10em}|p{10em}|]
\topline
Makro
&Význam
&Argumenty
&Vrací
\cr
\midline
SP\_TAG
&
&unsigned char *
\zlom název tagu&nic\cr
\midline
SP\_CONTROL
&jakákoliv položka\zlom formuláře&struct\zlom form\_control *
\zlom ona položka &nic\cr
\midline
SP\_TABLE
&získání tabulky pro\zlom překódování znakových sad&nic&struct conv\_table *
\cr
\midline
SP\_USED
&dotaz, zda se skutečně sází; nesází, pouze zjišťuje velikost textu\zlom kvůli tabulkám&nic&0=nesází se\zlom 1=sází se\cr
\midline
SP\_FRAMESET
&frameset&struct\zlom frameset\_param *
&struct\zlom frameset\_desc *
\cr
\midline
SP\_SCRIPT
&javascript ve\zlom
Interpretace začíná výrobou kontextu (js\_create\_context
). Při výrobě
kontextu se naalokuje struktura js\_context
a její položky se zinicialisují.
Pokračuje se naparsováním kódu, tedy zavoláním funkce js\_execute\_code
, které
se jako argument předá pointer na kontext a pointer na kód. Parser zdrojový kód
zkompiluje do podoby stromového mezikódu, nad nímž by šlo uvažovat o
optimalisacích. Toto řešení bylo zvoleno proto, že k parsování javascriptu lze
snadno použít utilit flex
(ev. lex
) a bison
(ev. yacc
). Tyto
nástroje jsou reentrantní způsobem, který pro naše způsoby připomíná použití
parního válce k louskání ořechu, tj. ve chvíli, kdy by se měl vyrobit
samomodifikující kód (což je u javascriptu obvyklé), by se interpretace značně
zdržovala, vůbec stranou necháváme fakt, že by bylo potřeba ošetřovat i
pravidelná přerušení interpretace, ke kterým dochází dosti často. Proto po
zavedení stránky proběhne přestavba zdrojového textu do pohodlnější (a rychleji
zpracovatelné) stromové podoby. V této podobě se kód interpretuje k tomuto účelu
specielně vyvinutým interpretem, který by měl mít možnost postihnout všechny
odstíny práce javascriptu. Bohužel některé vlastnosti javascriptu jsou dle
našeho názoru značně
odtažené od programátorského pohledu, nemluvě o tom, že autoři javascriptu tyto
partie používají zřídkakdy správně, proto bylo od některých položek upuštěno s
vyhlídkou na to, že buďto nejsou důležité, nebo se v některé z pozdějších verzí
dodělají. Jedná se zejména o funkci eval(string a)
, která má za běhu
javascriptu spustit vyhodnocování řetězce zadaného jako argument. Takovouto
funkci používají někteří programátoři například k tomu, aby vyvolali funkce
různých jmen namísto toho, aby toto rozlišili parametrem (například
funkce1();
místo funkce(1);
). Takovéto jednání je vyloženým
diletantismem a není důvodu nabízet mu oporu, zvláště je-li na práci dostatek
závažnějších problémů. Druhou vynechanou položkou je funkce sort
u pole,
která by sice mohla být užitečná, ale jednak si ji může člověk napsat v
javascriptu jinak, navíc by měla mnoho podobného funkci eval
.
Je-li skript zinterpretován, zůstávají jeho údaje v paměti, jelikož v rámci
stejného kontextu lze očekávat, že budou spouštěny "eventové handlery", tedy
ovladače událostí. Tyto se začasté odkazují na funkce definované v těle stránky
(v souladu se specifikací Javascript 1.1 od Netscape Corporation).
Datové struktury spojené se skriptem definitivně opouštějí paměť až ve chvíli,
kdy je stránka uživatelem opouštěna. Při této příležitosti se zavolá
funkce js\_destroy\_context
, která zruší celý kontext skriptu, tedy jeho
nosnou entitu.
Gramatiku javascriptu se podařilo dostat z normy Javascript 1.1. Poté, co jsme
ji implementoval a zkusili naparsovat několik stránek, jsme zjistili, že máloco
se tak liší, jako dnes provozované skripty a gramatika jim určená. Autoři
stránek náhodně vynechávají středníky na koncích statementů, divoce míchají
operátory vzetí hodnoty v poli a dotazu na člen objektu. Bylo tudíž nutné
poněkud gramatiku upravit. Jelikož jsme se však nechtěli od specifikací
odchylovat (v souladu s cíli projektu, mezi nimiž figuruje např. postavení
browseru, který bude zobrazovat korektní kod, o nekorektním se jasně řeklo,
že browser nesmí zhroutit, zato jej browser smí zinterpretovat přibližně
libovolně). Zvolili jsme toto řešení: Gramatiku jsme poupravili tak, aby
popsané gramatické nesmysly bylo možné provádět bez omezení, leč každý
přestupek proti normě je "oceněn" warningem. Hlášení warningů stejně jako
errorů lze vypnout. Pro účely vývoje stránky je vhodné si tyto zapnout,
na libovůli uživatele, který si stránky prohlíží, pak je, aby se nechal
informovat o zlozvycích autora, nebo ne.
Javascript disponuje nemalým množstvím typů proměnných, konstant a dalších,
interpret píšícím jedincům nepříjemných položek. Připouštíme rovnou, že ne
všechny konverze jsou implementovány (kupř. jsme kategoricky odmítli dělat
dekompilaci, tj. konverzi funkce do řetězce, která je v normě specifikována
jako zobrazení kanonického zdrojáku. Jednalo by se vlastně o další kompilátor,
jehož stavba by sice nebyla zásadně náročná, ale vzhledem k tomu, že jedinou
výhodou pro pisatele stránek, ev. jejich čtenáře, by byla, že si mohou
takovouto funkci v řetězci modifikovat, nebo nakonec dát vyhodnotit (chyby
v kódu takto odhalovat nelze), jediná věc, která vypadá rozumně, je udělat
"fake dekompilaci", tedy ať vypadá konvertovaná funkce jak chce, vždycky
napíšeme:
V Links je základní vlastností konečnost prováděných operací, jelikož
jedním ze základních cílů projektu byla stabilita. Platí invariant, že
žádný kus kódu nesmí být vykonáván neomezenou dobu (výjimkou je snad jenom
gethostbyname
). Jak je tomu v modulu javascriptu? Parsování zařizují
flex
a bison
, jejichž kód považujeme za konečný, tyto "lamače textu" nejsou
při práci vyrušovány interrupty. Po naparsování kódu je interpretace
"objednána" nastavením timeru (v této chvíli se provádění javascriptu přeruší).
Interpretace probíhá po pevných počtech kroků (100), tedy nejpozději po sto
iteracích interpretu (interně označovaných jako žvýknutí) je interpretace
přerušena a tím je zabráněno tomu, aby zlomyslný autor javascriptu browser
paralyzoval. Některé browsery mají problémy přežít např. tento kód:
Z každého rámu v HTML dokumentu (f\_data\_c
) vede ukazatel js
na strukturu
js\_state
, která obsahuje frontu skriptů, které se mají spustit, a ukazatel ctx
na kontext právě
běžícího skriptu.
js\_context
je hlavní struktura popisující kontext javascriptu. Z ní vede ukazatel
js\_tree
na interpretovaný strom, jehož uzly jsou ještě provázány spojovým seznamem.
Do stromu míří i pointer current
, který ukazuje na momentálně interpretovaný uzel.
Struktura parbuf
je zásobník otců, tedy opět ukazatelů do stromu. Pointer
namespace
ukazuje na globální namespace, neboli hashovací tabulku všech
identifikátorů ve stromě. Lokální namespace (lnamenspace
) je representován
strukturou plns
, ze které vede ukazatel na další lokální namespace (na obrázku není
nakreslen) a pointer ns
na hashovací tabulku jednotlivých identifikátorů. Přímo na
identifikátory se může odkazovat zásobník argumentů argbuf
.
Chyby jsou v javascriptu rozděleny do několika skupin:
Ke každému hlášení o chybě je připojena citace řádku, na kterém byla
zjištěna, proto může být citován pozdější řádek, kupř. jedná-li se například
o zapomenutý středník na konci řádku, je uživatel uvedoměn až s koncem
následného komentáře.
Příklad:
Celý modul je doslova prošpikován debugovacími nástroji. Lexikální analyzátor
umí vypisovat jednotlivé tokeny, které se čtou, syntaktický analyzátor zase
dovede hlásit, jaká redukce proběhla. Dojde-li k lexikální nebo syntaktické
chybě, lze těmito nástroji snadno zjistit, co není v pořádku. Je pravda, že
pro obyčejného uživatele se jedná o parní válec na ořechy, ale ve chvílích,
kdy gramatika nebyla úplně v pořádku, byly tyto nástroje nepostradatelné.
Stejně tak interpret mezikódu je osazen výkonnými hlásiči, které říkají,
v jakém stavu se interpret nachází (pokolikáté se prochází kterým uzlem
stromu, občas i co se vrací). Obsluha interních funkcí a proměnných je
neméně upovídaná. Hlásí vstup a výstup do ovladače od každé funkce. Přestože
debugovacích výstupů je poměrně mnoho, chybí tam občas konkrétní údaje
(čísla, která se napočítala apod.). Toto je chyba, ale ve chvíli, kdy
člověk loví chybu v interpretu, bývá dostatečné, když zjistí, mezi kterými
dvěma stavy se stalo něco divného, na interpret je stejně potřeba vzít
debugger a vypisovat si každou podezřelou veličinu.
V souboru listedit.c
jsou funkce a datové struktury umožňující
jednoduše nadefinovat nějaký seznam, se kterým bude uživatel Links
pracovat. Z využitím funkcí z listedit.c
se dají vytvořit velice
jednoduchým přídavným kódem například bookmarky, asociace, přípony, ....
Seznam může být buď plochý, nebo stromový. Plochý seznam je lineární
seznam, kde jedna položka následuje druhou. Ve stromovém seznamu jsou krom
položek ještě adresáře. V adresářích mohou být položky nebo další adresáře.
Obecné seznamy neřeší vyrábění seznamů, jejich ukládání na disk, čtení z
disku. To si musí implementátor obstarat sám.
Při zavolání funkce create\_list\_window
se uživateli Links zobrazí
okno se seznamem. Okno vypadá takto:
Ovládání okna je následující:
V hlavním okně jsou tato tlačítka (věci týkající se adresářů se
pochopitelně vyskytují pouze stromových seznamů):
Seznamy používají dvě významné datové struktury. První z nich je struct
list
. Tato struktura obsahuje vlastní seznam. Skládá se z těchto částí:
Druhá struktura je struct list\_description
, obsahuje popis seznamu.
Pro každou implementaci seznamu je potřeba vytvořit jednu takovouto
strukturu, ta se pak předává všem funkcím pracujícím se seznamy. Struktura
obsahuje tyto položky:
Struktura dále obsahuje tyto vnitřní proměnné, na které by implementace
seznamu neměla sahat, všechny by měly být při inicialisaci struktury nastaveny na
hodnotu 0.
\penalty -10000
Funkce viditelné z modulu listedit.c
jsou tyto:
Pokud chcete přidat nový seznam, nejprve vytvořte novou instanci struktury struct
list\_description
a nainicialisujte ji příslušnými hodnotami a funkcemi, které
napíšete. Pokud budete chtít vytvořit okno, zavolejte
create\_list\_window
s Vaším seznamem.
Každý člen seznamu má u sebe proměnné: hloubka, typ (adresář/položka), flag
otevřeno/zavřeno, ukazatel na otce.
Když uživatel zmáčkne tlačítko "Přidat položku", vyrobí se nová položka (zavolá se
funkce new\_item
), která se nepřidá do seznamu. Poté se zavolá funkce
edit\_item
na editaci položky. Po úspěšné editaci položky (zmáčknutí "OK")
se teprve položka přidá do seznamu. Při zmáčknutí "Zrušit" se položka
smaže.
Při editování položky (uživatel zmáčkne tlačítko "Edit") se vytvoří nová
položka, zkopíruje se do ní obsah té původní (zavolá se copy\_item
) a opět
se zavolá edit\_item
. Jestliže uživatel zruší editaci tlačítkem "Cancel",
položka se smaže. V opačném případě se obsah položky zkopíruje zpět do
původní (opět pomocí copy\_item
) a položka se smaže.
Při zmáčknutí "Cancel" tedy funkce edit\_item
musí položku smazat. Při
zmáčknutí "OK" je zavolána funkce, kterou edit\_item
dostane jako argument
(viz výše).
Použitý princip umožňuje závodění. V "ideálním případě" se totiž může stát,
že výše popsaný test selže a tedy bude okno seznamu otevřeno vícekrát.
Jelikož je vysoce nepravděpodobné, že se toto uživateli podaří (kliknout ve
více oknech současně na otevření okna se seznamem, a ještě mít stěstí, že
operační systém naschedulujuje oba procesy ve "vhodném" pořadí), tak by
vynaložené úsilí na implementaci precisního zamykání bylo neadekvátní k
výsledku. Proto byla zvolena jednodušší varianta.
Pokud chcete přidat nový .c
soubor do distribuce, editujte soubor
Makefile.am
a na řádku začínající links\_SOURCES=
připište název souboru (včetně
přípony .c
). Pak spusťte rebuild reconf
a nechte ho doběhnout.
Jestliže přidávaný soubor není zdrojový kód (ani jeden ze souborů .c
,
.h
, .inc
), tak ho přidejte do Makefile.am
, ale na řádku začínající
EXTRA\_DIST=
. Tyto soubory budou přidány do distribuce při spuštění make
dist
. Po přidání je opět potřeba spustit rebuild reconf
.
K přidání nové kódovací tabulky vlezte do adresáře Unicode
a proveďte následující.
Postup bude demonstrován na přidání kódování CP 852:
Po provedení této procedury je potřeba rekompilovat prohlížeč, aby se tabulka dostala i
do binárního souboru prohlížeče.
Zde bude popsán modelový postup, jak přidat nový grafický formát xbm
. Jiný grafický
formát se přidává analogicky.
Pokud přidávaný dekodér používá nějaké externí knihovny, je potřeba do skriptu
configure
přidat test na tuto knihovnu a možnost vypnutí tohoto dekodéru. Do souboru
configure.in
přidejte na začátek (k ostatním podobným blokům) blok (uveden příklad
pro knihovnu jpeg):
\verbatim
{AC_ARG_WITH(libjpeg, [ --without-libjpeg compile without JPEG support],
[if test "$withval" = no; then disable_jpeg=yes; else disable_jpeg=no; fi])
cf_have_jpeg=no
if test "$disable_jpeg" != yes ; then
AC_CHECK_HEADERS(jpeglib.h)
AC_CHECK_LIB(jpeg, jpeg_destroy_decompress)
if test "$ac_cv_header_jpeglib_h" = yes && test
"$ac_cv_lib_jpeg_jpeg_destroy_decompress" = yes; then
AC_DEFINE(HAVE_JPEG)
cf_have_jpeg=yes
image_formats="$image_formats JPEG"
fi
fi}
Všechen kód pro nový grafický formát dejte podmíněně kompilovat, pokud je definováno
příslušné makro, například HAVE\_JPEG
Pokud je knihovna nalezena a prohlížeč se bude kompilovat s podporou přidávaného
grafického formátu, musíte do proměnné image\_formats
přidat název Vašeho formátu,
který se má vypisovat po doběhnutí configure
scriptu při vypisování výsledků.
V předchozím příkladu testu knihovny se již do proměnné přiřazuje. Do
proměnné přiřadíte takto:
Při psaní funkcí xbm\_start
a xbm\_restart
musí platit následující invarianty:
Když se zná hlavička obrázku, tak se do cimg
vyplní položky width
, height
,
buffer\_bytes\_per\_pixel
, red\_gamma
, green\_gamma
, blue\_gamma
, strip\_optimized
a zavolá se
header\_dimensions\_known(cimg)
. To vytvoří buffer vyplněný pozadím (pokud je alfa
,
tak průhlednou) a restart()
do toho bufferu začne vyplňovat byty, jak je dekóduje. V případě, že
narazí na chybu, zavolá end(cimg)
a return
. Když dekódování skončí (další byty se
můžou ignorovat a obrázek se již nebude měnit), zavolá se také end(cimg); return;
.
Pokud se v xbm\_start
něco nepodaří, zavolá se end(cimg); return;
.
Strukturu xbm\_decoder
si musí dekodér sám naalokovat, vyplnit si do něj,
co potřebuje, a na konci ji musí zase uvolnit.
Pokud se zavolá end()
, tak už nebude zavolán restart()
. start()
se
zavolá jenom jednou úplně na začátku, aby se vyrobil dekodér. Do dekodéru mezi
restart
y nikdo cizí nesahá. end()
může volat destroy()
, jinak se
destroy
nemůže zavolat z funkcí dekodéru. restart()
i destroy()
se můžou
mimo funkce dekodéru volat kdykoliv. restart()
dostane blok dat, která se mají
dekódovat.
Zde uvedeme modelový postup, jak přidat do Links francouzštinu.
Přidání jiného jazyka je analogické. Všechny popisované operace
provádějte v adresáři intl
.
Tato kapitola popisuje přidání nového řetězce do jazyků. Všechny
popisované operace se provádějí v adresáři intl
. Na modelovém
postupu ukážeme, jak se přidá text "Welcome to links!", v češtině "Vítej v programu links!".
Přidání jiných řetězců je analogické.
Podobný postup se provádí při přidávání horkých kláves. Rozdíl je
pouze v tom, že konstanta začíná T\_HK\_
, jinak je postup stejný.
Pokud chcete vytvořit nový font (toto dělejte jen v případě, že by se znaky
kryly, zbytečně mnoho adresářů s fonty by mohlo prohlížeč zpomalit), řiďte
se následujícím postupem.
Soubory musí být šedotónové PNG obrázky, pokud budou barevné, budou prohlížečem
zkonvertovány na černobílé a pouze zabírat více místa. V obrázku je bílá
interpretována jako "inkoust", černá jako "papír", přechod mezi nimi jako
příslušné namíchání "inkoustu" a "papíru". Aspect ratio obrázku se ignoruje,
alpha kanál se kombinuje s pozadím. Na velikosti obrázků nezáleží, všechny
obrázky budou zkonvertovány na stejnou výšku. Výška se doporučuje kolem 112
pixelů. U monospaced fontů (s pevnou šířkou znaku) musí mít všechny obrázky
stejný poměr výšky k šířce.
Doporučujeme, aby obrázky byly šedotónové, bez alphy, s gamma 1.0, čtvercovými
pixely, bez extra informací jako jsou například komentáře, čas, datum, barevné
profily, pozaďová barva, offset, .... To je vše je z důvodu úspory místa a
také proto, že tyto informace jsou ve fontu naprosto zbytečné a nevyužijí se.
Tento odstavec popisuje, jak font ve formátu *.pfb
, *.afm
, *.pfa
(nebo jeho části) přidat do prohlížeče. Vstupem procedury je font ve
formátu, který je schopen přečíst Ghostscript a výstupem sada obrázků ve
formátu PNG, které se přidají do adresáře graphics/font/ Přidávání fontů je poloautomatické s použitím několika scriptů a pomocných
programů, které jsou přibaleny v CVS vydání Links. Tyto programy nejsou v
běžné distribuci, protože pro instalaci a běh prohlížeče nejsou potřeba.
Programy se kompilují také bez použití configure
skriptu, a vyžadují ke
svému běhu striktnější verzi libpng
než samotný prohlížeč (nejsou tam
workaroundy na schopnosti libpng
, které chybějí ve starých verzích).
Procedura také vyžaduje, aby na systému byl nainstalován Imagemagick (program
convert
). Během přidání je možno vygenerovat agregované symboly, kde už
stačí jen jednoduchá editace GIMPem, a můžeme tak dodělat chybějící akcenty z
fontů, které nemají příslušné symboly.
Celý proces probíhá následovně: Uživatel zadá do souboru Fontmap
, který
chce font, a pak pustí skript makefont
. Výstupem makefont
u bude hromada
souborů ve formátu PNG v adresáři font/new
. Program makefont
provádí
následující akce:
Komentáře se dělají pomocí znaku \%
na začátku řádku. Buď se tam může
napsat rovnou jméno souboru s fontem (pokud je v adresáři kde ho Ghostscript
najde, 1. řádek), nebo cesta (2. řádek) a nebo jméno fontu který už je v
Ghostscriptu nadefinovaný (3. řádek). Vybereme si 1 z nich, modifikujeme podle
našeho fontu a ostatní zakomentujeme. Když máme font pro ghostscript (většinou
*.pfb
a *.afm
, to *.pfb
jsou písmenka a *.afm
je metrika), tak
se dá pomocí pomocných programů a skriptů přidat.
Pomocí makefont
se vygenerují do adresáře font/new/
písmenka která jsou ve
fontu přímo. Písmenka s akcentem která tam nejsou, ale je tam to písmenko a
akcent se vygenerují že v tom výsledném obrázku je vlevo písmenko, mezi tím
takový kostkovaný pruh a vpravo akcent. Pak se vezme GIMP a akcent se přendá
nad písmenko do esteticky hodnotné polohy a odřízne se kostkované pruh a to, co
je vpravo od kostkovaného pruhu. Pak se to uloží do obrázku zpět. Při troše
zručnosti takovéto akcentování jde celkem rychle.
Přidání nového znaku do již existujícího fontu je jednoduché. Řiďte se
následujícím postupem. Pokud možno přidávejte znaky do již existujících
adresářů, protože zbytečně mnoho adresářů s fonty by mohlo prohlížeč zpomalit.
Soubory musí být šedotónové PNG obrázky, pokud budou barevné, budou prohlížečem
zkonvertovány na černobílé a pouze zabírat více místa. V obrázku je bílá
interpretována jako "inkoust", černá jako "papír", přechod mezi nimi jako
příslušné namíchání "inkoustu" a "papíru". Na velikosti obrázků nezáleží,
všechny obrázky budou zkonvertovány na stejnou výšku. Aspect ratio obrázku se
ignoruje, alpha kanál se kombinuje s pozadím. Výška se doporučuje kolem 100
pixelů.
Doporučujeme, aby obrázky byly šedotónové, bez alphy, s gamma 1.0, čtvercovými
pixely, bez extra informací jako jsou například komentáře, čas, datum, barevné
profily, pozaďová barva, offset, .... To je vše je z důvodu úspory místa a
také proto, že tyto informace jsou ve fontu naprosto zbytečné a nevyužijí se.
Pokud přidáváte nové znaky do monospaced fontů (s pevnou šířkou znaku) musí
mít nové obrázky stejný poměr výšky k šířce jako původní obrázky.
Pokud chceme přidat do prohlížeče unicode znaky, které jsou pro nás
důležité, ale nemáme od nich soubor čitelný Ghostscriptem, ale pouze
papírovou předlohu a scanner, stačí písmo nascannovat, nahrát do GIMPu,
invertovat, oříznout tak, aby účaří bylo na 5/24 výšky (počítáno odspoda),
vhodně stranově oříznout, pomocí image -> colors -> levels
oříznout
zašuměné bílé a černé partie (bez změny gammy, předpokládáme, že scanner
jako většina scannerů generuje výstup s gammou 1.0) a uložit do souboru
xxxx.png
, kde xxxx
je hexadecimální kód Unicode znaku.
Zde najdete ukázkový postup, jak přidat nový grafický driver do Links. Postup bude
demonstrován na driveru pro framebuffer, přidání jiného driveru je zcela analogické.
,
a položky
konstrukcí
. Záložky se ukládají jako odkaz (tedy pomocí tagů ,
Links bookmarks
Links
Historie
Konfigurační soubory
enable_global_resolution 1
js_recursion_depth 1000
js_memory_limit 2k
bookmarks_codepage ISO-8859-2
bookmarks_file "/home/brain/.links/bookmarks.html"
ftp.anonymous_password "somebody@host.domain"
terminal "linux" 1 1 5 ISO-8859-2
terminal "xterm" 0 0 0 ISO-8859-2
user_gamma 0.880000
bfu_aspect 1.000000
aspect_on 1
dither_letters 1
Obecně o programování Links
C jazyk
// tohle v cc neprojde
/* je potřeba používat tyto komentáře */
fn()
{
nějaký kód....
label:
}
je potřeba nahradit
fn()
{
nějaký kód....
label:;
}
struct bla {
int a, b;
;
export CC=cc
./configure
make
Pak se bude kód kompilovat ANSI C místo GNU C. Vypíše to spoustu warningů, ale
výsledný kód je funkční.
Přidávání zdrojáků
#include "cfg.h"
#include "links.h"
Používání autoconfu
definuje SYMBOL v config.h
(např. AC_DEFINE(CHCEME_FLEXI_LIBU)). Symbol se také
musí vyskytovat v souboru acconfig.h
.
vyrobí program, který bude na začátku obsahovat includy, pak main()$\{$ a tělo
main a pak ukončovací $\}$. Pokusí se program slinkovat, pokud se to povede,
vykoná úspěch-skript
, jinak neúspěch-skript
.
pokud je ac\_cv\_proměnná
v config.cache
, tak ji nahraje z té cache; jinak vykoná
skript. Předpokládá se, že skript nastaví ac\_cv\_proměnnou
. Ta je uložena do
config.cache
a při dalším puštění se už skript nevyvolává.
Velikosti dat
Alokace paměti
Chyby
Syntax jako u printf
. Vypíše chybové hlašení. Používá se k ošetřování
různých vnějších chyb, jako třeba, že došla paměť (je voláno přímo z
mem\_realloc
). Kód pokračuje za funkcí.
Vypíše DEBUG MESSAGE at file:line: str\dots
a zastaví běh na jednu sekundu, aby
bylo možno zprávu přešíst. Syntax je jako u printf
. Používá se při debugování,
neměla by se vyskytnout nikde ve výsledném kódu.
Pro ošetřování "can't happen" situací. Funkce vypíše hlášení INTERNAL ERROR
at file:line: str \dots
, zastaví browser a způsobí core dump. Syntax je jako
u printf
. Pokud si je člověk jist, že nějaká podmínka má platit, ale že by
platit nemusela, pokud se někde vyskytl bug, měl by tuto podmínku otestovat, a
pokud neplatí zavolat internal
. Čím dřív se bug zachytí, tím líp se hledá,
proto by se tato funkce měla hojně používat. Funkce se může (a měla by se)
vyskytovat ve výsledném hotovém kódu.
Nedělá vůbec nic. Slouží jen k obelhání překladače, aby neprováděl
optimalizace. Ano --- i gcc 2.7.2.1 má bugy v optimalizaci.
Řetězce
Převede znak na velká písmena.
Funguje jako memcmp
, ale ignoruje velikost písmen. Je taky zaručeno (což v
memcmp
není!), že nebude sahat za první neshodující se byte, takže je možné
použít k porovnávání začátků řetězců.
Zkopíruje řetězec do nově alokovaného místa. Výsledek je nutno po použití
uvolnit pomocí mem\_free
.
Zkopíruje n
bytů ze str
do nově alokované paměti, přida nulu na konec a
vrátí pointer.
Realokuje řetězec str1
a zkopíruje na jeho konec str2
. str1
je
pointer na pointer na řetězec - může se změnit při realokaci. Funkce není
příliš rychlá, proto je lepší použít následující funkce.
Řetězce s prealokací
Alokuje řetězec pro použití dalších funkcí. Vrácený pointer reprezentuje
prázdný řetězec.
Přidá řetězec str2
na konec řetězce str
. Řetězec str
musel být
alokován pomocí init\_str()
.
Jako add\_to\_str
, ale přidá len2
bytů z adresy str2
. Byty z adresy
str2
nebudou odalokovány.
Přidá do řetězce str
jeden znak chr
.
Přidá do řetězce str
číslo num
v dekadickém zápise.
Přidá číslo v "lidsky čitelném zápise", čili s použitím písmenek "k" (kilo) a
"M" (mega). Kilo vyjadřuje 1024 a mega vyjadřuje 1048576 (což je 1024*1024).
Jinak je funkce stejná jako add\_num\_to\_str()
.
{
int l = 0;
unsigned char *str = init_str();
add_to_str(&str, &l, "Text:");
add_chr_to_str(&str, &l, ' ');
add_num_to_str(&str, &l, 10);
printf(str);
mem_free(str);
}
{
int l = 5;
unsigned char *str = stracpy("12345");
add_to_str(&str, &l, "bla");
}
Funkce stracpy
nedělá potřebnou prealokaci, takže výsledkem bude vystřílená
paměť.
Seznamy
struct polozka_seznamu {
struct polozka_seznamu *next;
struct polozka_seznamu *prev;
/* a tady jsou uz dalsi volitelne polozky */
int a, b;
unsigned char c;
}
Hlavu seznamu deklarujeme takto:
struct list_head hlava_seznamu = { &hlava_seznamu, &hlava_seznamu
;}
Přidá položku do seznamu těsně za hlavu, první argument musí být pointer na struct
list\_head
, druhý argument je pak položka seznamu.
prvek\_v\_seznamu
je už zařazen v nějakém seznamu, makro přidá
položku položka\_seznamu
do seznamu za příslušný prvek.
Expanduje se jako for cyklus, který pro proměnnou proměnná
projde všechny
prvky seznamu. Tělo cyklu nesmí smazat aktuální prvek.
Jako foreach
, ale projde seznam pozpátku.
Zavolá mem\_free
na všecky prvky seznamu a seznam vyprázdní (tedy odstraní
ze seznamu všechny prvky, takže ze seznamu zůstane pouze hlava).
Vrátí 1, pokud je seznam prázdný, jinak vrátí 0.
Jak používat grafiku (textový vs. grafický mód)
Links má běžet v textovém i grafickém módu. Zkompilovat jde buď jen pro
textový mód nebo pro textový i grafický mód (pomocí ./configure
--enable-graphics
). V grafickém módu se pouští s parametrem -g
.
if (!F) {kód pro textový mód...
#ifdef F
else {kód pro grafický mód...
#endif
}}
Existují další makra pro usnadnění rozhodování:
Vrátí hodnotu x
, pokud běží browser v textovém módu, a y
, pokud běží v
grafickém.
Zavolá interní chybu, pokud běží browser v textovém módu. Lepší zavolat interní
chybu, než pak spadnout při sahání na neinicializované struktury...
Zavolá interní chybu, pokud běží browser v grafickém módu.
Psaní javascriptu
#ifdef JS
/* kód, který se provádí při zapnutém javascriptu */
#endif /* JS */
Pokud některé javascriptové funkce nebo kusy kódu musí být v kódu i při vypnutém
javascriptu, použije se opět podmíněný překlad. Jelikož taková funkce při vypnutém
javascriptu obvykle nic nebude dělat, kód bude vypadat například takto:
#ifdef JS
void jsint_scan_script_tags(struct f_data_c *fd)
{ /* kód, který se provádí při zapnutém javascriptu */
#else
void jsint_scan_script_tags(struct f_data_c *fd)
{
}
#endif}
Debugování javascriptu
Formáty obrazových dat
Formát obrazových dat je charakterizován jednotlivými přítomnými kanály, jejich hloubkou,
paměťovou organizací a gammou (kromě alphy, která nemá gammu). Fotometrickou
reprezentací dále rozumějme veličinu přímo úměrnou množství fotonů, které vycházejí
z daného pixelu na monitoru uživatele (nikoliv tedy množství světla na scéně
při pořizování snímku nebo množství světla, které umělec zamýšlel, aby vycházelo z monitoru uživatele).
Fotometrická reprezentace budiž definována pouze tehndy, je-li prohlížeč správně
okalibrován na příslušný display.
Členění do modulů
Select smyčka
Základem programu je select smyčka
nebo též scheduler
. V této části se plánují
všechny události, které mají nastat, a odtud se volají jednotlivé části prohlížeče.
Select smyčka je kooperativní scheduler. Všechny části prohlížeče musí být napsány tak,
aby v nich řízení nezůstávalo příliš dlouho, protože by nemohly být volány jiné části,
což by se například projevovalo nereagováním na pokyny uživatele. Select smyčka se
nachází v souboru sched.c
, na obrázku zobrazena není, protože funkce scheduleru jsou
volány ze všech částí prohlížeče, což by obrázek učinilo nepřehledným. Celý život linkse
se odehrává ve funkci select\_loop
, která pomocí funkce select
čeká na ruzné
události.
Session
Object requester
Sched
Cache
Url
Http, https, finger, ftp, file
Cookies
Jsint
Javascr.l --- lexikální analýza
Typy tokenů
Řidícím slovům stačí pouze long
říkající vše. Jedná-li
se o nějaký literál, pak pro boolské literály jsou použity dva různé tokeny
(TRUE
a FALSE
), pro nullový literál token NULL
. Numerický
literál odesílá ještě v proměnné yylval
buďto hodnotu celého čísla, nebo
pointer na necelé. yylval
je typu long
kvůli přetypovatelnosti na integer i
pointer. Řetězce posílají v proměnné yylval
ukazatel na místo v paměti, kde se
řetězec nachází.
Identifikátory
Každemu identifikátoru je již při lexikální analýze
přiřazen klíč, pod kterým bude v celém programu vystupovat (tento klíč
je jednoznačný i pro "vnořené" identifikátory, tedy ať už se identifikátor
vyskytuje jako proměnná a stejně se jmenuje kupř. nějaká metoda nějakého
objektu, budou mít tyto klíče stejné. Kde se objekt identifikátorem odkazovaný
v paměti nachází se zjišťuje z "adresného prostoru", který je až záležitostí
interpretu mezikódu. Při lexikální analýze tedy vzniká jakýsi "namespace",
který přiřazuje každému identifikátoru nějaký klíč. Indexování proměnných
klíčem bylo vybráno proto, že porovnat dva longy je podstatně rychlejší,
než testovat shodu dvou řetězců (zdržení se realizuje za každý výskyt
proměnné ve zdrojovém textu, nikoliv za každý dotaz na ni při interpretaci).
Javascript.y --- syntaktická analýza
Syntaktická analýza
operátor, ukazatel na první argument, ukazatel na druhý argument, \dots,\\ukazatel na
šestý argument.
Generátor mezikódu
Fosilie
Funkce terminál a neterminál. V minulosti se jevilo jako dobrý
nápad rozlišovat, co je terminál (nemá potomky typu pointer, ale hodnota)
a co neterminál (rodič nějakých terminálů nebo neterminálu). Posléze se
však ukázalo, že uzly jsou natolik heterogenní, že takovéto dělení
je úplně zbytečné. Až bude trocha času na civilizování kódu, tak jednu
z těchto funkcí vymažu (možná už jsem to udělal, ale nepamatuju se).
Builtin
Ipret --- interpret mezikódu
Vztahy k okolí
Interpretace začíná zavoláním js\_create\_context
, která vytvoří strukturu
js\_context
(popsanou výše). V této funkci jsou do namespaců
a addrspaců doplňovány vestavěné funkce.
js\_destroy\_context
, která zruší kontext a tím i všechna data se
skriptem spojená.
View a view\_gr
Img a img\_cache
HTML parser: moduly html\_r, html\_gr, html, charsets
Moduly bfu a menu
Grafické ovladače
Dip, dither, font\_data a font\_cache
Vnitřní struktury a jejich komunikace
Princip jednotlivých částí
Fonty
Fonty jsou obdélníky s barvou pozadí, na kterých je nakreslené písmeno barvou
popředí. Obdélníky se nemohou překrývat. V následujících řádkách textu se obdélníky
na výšku dotýkají.
Při jejich tisknutí se nepoužívají žádné fontovací funkce X, svgalib,
pmshell ani ničeho podobného. Používají se pouze funkce pro tištění bitmap. Bitmapy jsou
renderovány programem (čímž je zaručeno, že bude moci být 100\
vypadat) přímo ve formátu vhodném pro dané výstupní zařízení (záleží na barevné hloubce)
a pak jsou kresleny na obrazovku.
Gamma
HTML parser a sazeč
HTML parser
void parse\_html(unsigned char *html, unsigned char *eof, void (*put\_chars) (void*, unsigned char*, int), void (*line\_break) (void*), void *(*special) (void*, int, ...),
void*data, unsigned char *head)
Gramatika
Typové konverze
function funkce(){alert("Funkce je interní!");
}
Z důvodů ladění interpretu je pravděpodobně občas možné udělat normou zakázané
vzetí nedefinované hodnoty. K tomuto došlo při vývoji. Aby interpret nepadal
tak často při dotazech na dosud neimplementované položky, bylo možné dostat
hodnotu undefined
. V současné době by mělo být již opraveno, ale vzhledem
k počtu možných konverzí, je pravděpodobné, že takováto chyba ještě někde
přežívá.
Scheduler
Zobrazování dialogových
nebo jen hrozivých okének (alert, confirm, prompt
) interpretaci přeruší
do chvíle, kdy jsou tato okénka uživatelem zrušena (bráníme se tak možnosti
diskreditovat browser například tímto kódem:
který rovněž některé browsery těžko snášejí. Toto však, s ohledem
na možnost nastavit si timery není dostatečné, proto je každé okno
vyprodukované javascriptem opatřeno tlačítkem "Kill script", které vyvolá
uživatelskou chybu (zavolání funkce js\_error
spolehlivě interpretaci zastaví),
na ploše pak zůstane viset několik okének, která bude muset uživatel
"doklepat".
Struktury javascriptu
Hlášení chyb
a=5
/* Tohle je ten
* roztahaný
* komentář, který zaviní,
* že je zobrazena až
* TATO ŘÁDKA */
Ladění
Obecné seznamy
Úvod
Ovládání uživatelem
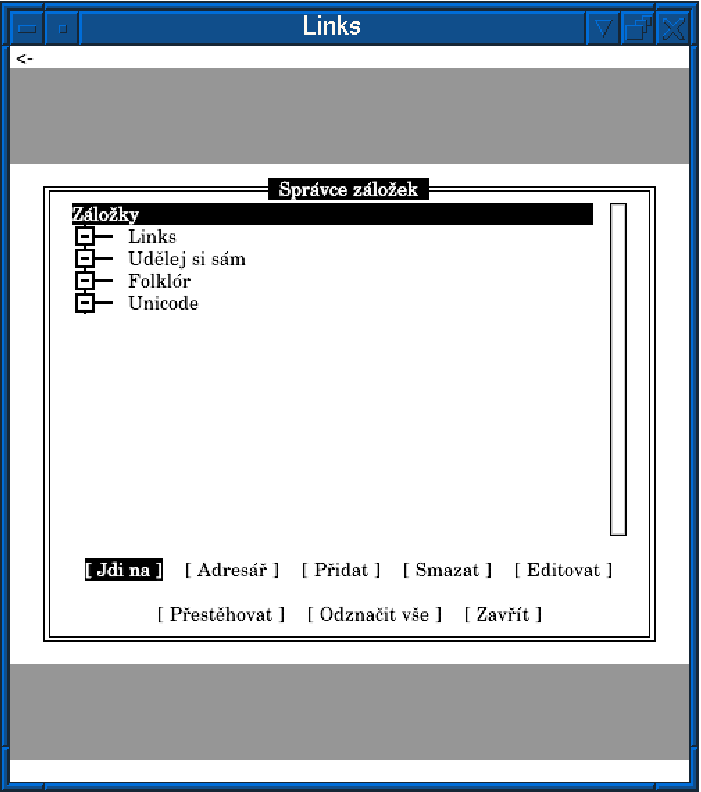
Datové struktury a funkce
Funkce
Vytvoří okno pro práci se seznamem. Jako argumenty dostává popis seznamu,
pointer na seznam, terminál, na kterém se má okno vytvořit, a session.
Překreslí obsah okna se seznamem.
Znovu inicialisuje okno do stavu jako po spuštění create\_list\_window
. To
znamená přesune kurzor a výhled na seznam na začátek a překreslí.
Implementace seznamu
Stromový seznam
Přidávání a editace položek --- funkce edit\_item
Přístup do seznamu z více oken Linksu
Struktury nejsou odolné proti více paralelním přístupům (například ve
se ve struktuře ukládá pozice kurzoru v okně atd.), proto je přístup z
více oken zakázán. Funkce create\_list\_window
nejprve nastaví ve struct
list\_description
proměnnou open
na 1, při zavření hlavního okna se proměnná
open
nastaví na 0. Pokud se při zavolání funkce create\_list\_window
zjistí,
že proměnná open
je již nastavena na 1, uživateli se objeví upozornění, že okno
je již jednou otevřeno a že ho nejprve musí zavřít. Pochopitelně toto platí
pro stejný seznam. Není problém mít otevřeno více oken, každé od jiného
seznamu.
Přidávání nových částí prohlížeče
Přidání souboru do distribuce Linksu
Jak přidat novou překladovou tabulku kódování
CP 852
"cp852", "852"
cp852
Přidávání nového grafického formátu
#include "cfg.h"
#ifdef G
#include "links.h"
Úplně na konec souboru napište:
#endif /* G */
void xbm_start(struct cached_image *cimg);
void xbm_restart(struct cached_image *cimg, unsigned char *data,
int length);
kde data jsou vstupní data
obrázku, length
je délka dat a cimg
popisuje
dekodér obrázku.
/* xbm.c */
#ifdef G
void xbm_start(struct cached_image *cimg);
void xbm_restart(struct cached_image *cimg, unsigned char *data,
int length);
#endif /* G */
image_formats="$image_formats JPEG"
Přidávání nového jazyka
french
T__CHAR_SET, "ISO-8859-1",
T__LANGUAGE, "French",
Přidání nového řetězce do jazykových překladů
T_WELCOME_TO_LINKS, "Welcome to links!",
Nezapomeňte na čárku na konci řádky!
T_WELCOME_TO_LINKS, "Vítej v programu links!",
Řetězec bude v kódování ISO 8859-2.
Přidání nového fontu
family-weight-slant-adstyl-spacing
23aa.png
0020.png
30bf.png
new_century_school
century_school_book
new_century_school_book
century
Přidávání fontů z Ghostscriptu
Kterak postupovat jako uživatel
Proto tam nechte defaultní hodnoty:
float font_pos=300;
float font_height=392.9619;
float h_margin=100;
float v_margin=120;
float paper_height=842;
/Links-generated (c059016l.pfb) ;
/Links-generated (/usr/local/share/ghostscript/fonts/c05906l.pfb);
/Links-generated /CenturySchL-Bold ;
#ifdef HIRAGANA
a tam je tabulka copy$[]$
a merge$[]$
. Copy
říká která písmenka se z fontu
mají okopírovat rovnou a merge
říká ty akcentované co se pak budou lepit
GIMPem. V copy$[]$
je vždy po sobě číslo znaku ve fontu ghostscriptu (0--255) a
číslo znaku v unicode (0--65535). V merge
jsou trojice: číslo znaku v
ghostscriptu, číslo příslušného akcentu v ghostscriptu, a číslo v unicode na
který se to má zmergovat. Pokud v clip.c
pro příslušné písmo tyto tabulky
nejsou, tak si přidáme \#define
a připíšeme si je. Můžeme stávající tabulky také
opravit, když zjistíme že je v nich chyba. Nejlépe se tabulky píšou tak, že si
dáme v Xech do 1 okna gv letters.ps
a do vedlejšího prohlížeč s unikódovými
tabulkami z http://www.unicode.org/
. Do třetího okna dáme vi clip.c
a vizuálně
hledáme ke každému unikódovému znaku odpovídající znak v letters.ps
a rovnou to
píšeme do zdrojáku clip.c
.
export hundred_dpi=1703
export top_promile=198
export bottom_promile=238
Přidání nových znaků do existujícího fontu
23aa.png
0020.png
30bf.png
Přidávání fontů z tištěné předlohy
Přidání grafického driveru
AC_ARG_WITH(fb, [ --without-fb compile without Linux Framebuffer
graphics driver], [if test "$withval" = no; then disable_fb=yes;
else disable_fb=no;fi])
A kód na detekci takto:
if test "$disable_fb" != yes ; then
AC_CHECK_HEADERS(linux/fb.h)
AC_CHECK_HEADERS(linux/kd.h)
AC_CHECK_HEADERS(linux/vt.h)
AC_CHECK_HEADERS(sys/mman.h)
if test "$ac_cv_header_linux_fb_h" = yes
&& test "$ac_cv_header_linux_kd_h" = yes
&& test "$ac_cv_header_linux_vt_h" = yes
&& test "$ac_cv_header_sys_mman_h" = yes
&& test "$ac_cv_header_sys_ioctl_h" = yes
&& test "$cf_have_gpm" = yes; then
AC_DEFINE(GRDRV_FB)
drivers="$drivers FB"
fi
fi
#undef GRDRV_FB
#include "cfg.h"
#ifdef GRDRV_FB
#include "links.h"
a na konec napište
#endif /* GRDRV_FB */
struct graphics_driver fb_driver={
"fb",
fb_init_driver,
init_virtual_device,
shutdown_virtual_device,
fb_shutdown_driver,
fb_get_driver_param,
fb_get_empty_bitmap,
fb_get_filled_bitmap,
fb_register_bitmap,
fb_prepare_strip,
fb_commit_strip,
fb_unregister_bitmap,
fb_draw_bitmap,
fb_draw_bitmaps,
NULL, /* fb_get_color --- filled in fb_init_driver */
fb_fill_area,
fb_draw_hline,
fb_draw_vline,
fb_hscroll,
fb_vscroll,
fb_set_clip_area,
fb_block,
fb_unblock,
NULL, /* set_title */
0, /* depth (filled in fb_init_driver function) */
0, 0, /* size (is empty) */
GD_DONT_USE_SCROLL, /* flags */
;}
#ifdef GRDRV_FB
extern struct graphics_driver fb_driver;
#endif
a do inicialisace pole graphics\_drivers
přidejte na konec před NULL řádek s grafickým driverem pro
framebuffer. Inicialisace tedy bude vypadat asi takto:
struct graphics_driver *graphics_drivers[] = {
#ifdef GRDRV_PMSHELL
&pmshell_driver,
#endif
#ifdef GRDRV_ATHEOS
&atheos_driver,
#endif
#ifdef GRDRV_X
&x_driver,
#endif
#ifdef GRDRV_SVGALIB
&svga_driver,
#endif
#ifdef GRDRV_FB
&fb_driver,
#endif
NULL
;}